HTML - HyperText Markup Language - ist eine formale Sprache, die dazu dient, Inhalte in einem Dokument
- zu strukturieren
- zu verbinden.
Für das Verbinden von Inhalten sind Hyperlinks zuständig. Dabei ist es egal, ob die verknüpften Inhalte im selben Dokument stehen oder sich in anderen Dokumenten irgendwo im Internet befinden.
Für die Strukturierung gibt es in HTML einen ganzen Satz von Befehlen und Anweisungen. Wenn man mit diesen Anweisungen umgehen will, lohnt es sich, ein paar Sachen im Hinterkopf zu behalten:
- Bei Befehlen und Anweisungen wird nicht zwischen Groß- und Kleinschreibung unterschieden
- Zeilenumbrüche, Tabulatoren oder mehrfache Leerzeichen im Text werden immer zu einem Leerzeichen zusammen gefasst
- die Sprache HTML ist gewachsen. D.h.: HTML ist nicht vollständig, ist nicht konsistent, hat Redundanzen.
Ein HTML Dokument besteht aus Elementen. Elemente werden definiert durch Marken und bestehen aus Attributen und einem Inhalt.
Nach Außen, für Autoren, stellen sich Elemente als Marken oder Markierungen oder - auf Englisch - tags dar. Intern, d.h. aus der Sicht des Browsers, haben Elemente eine definierte innere Struktur und einen definierten Zusammenhang mit anderen Elementen. Alle Elemente, ihre innere Struktur und ihre äußeren Beziehungen, bilden im Browser das DOM, das Dokument Object Model.
Attribute
Attribute zu Elementen definieren Eigenschaften
Ein Element besteht aus einer öffnenden Marke, dem Inhalt und der schließenden Marke. Soweit so gut.
Darüber hinaus können Elemente mit Attributen versehen werden. Über Attribute hat man die Möglichkeit, unterschiedliche Eigenschaften eines Elementes zu bestimmen.
Attribute bestehen aus einem Namen und einem Wert, einer Ausprägung. Der Wert wird einem Attribut per Gleichheitszeichen =
zugewiesen.
Attribute werden zusammen mit ihrem Wert in der öffnenden Marke nach dem Namen des Elementes definiert.
<Elementname Attribut="Wert">
Welche Art von Wert eingetragen werden kann, hängt vom jeweiligen Attribut ab. Manchen kann Freitext, sogar ganze Sätze, zugewiesen werden, manche vertragen nur numerische Werte oder Werte aus einer vorgegebenen Liste. Trägt man etwas ein, das der Browser nicht versteht, wird der Eintrag stillschweigend ignoriert.
Die Werte von Attributen werden am besten immer in doppelte Anführungszeichen gesetzt. Bei manchen ist es nicht notwendig, bei manchen manchmal nicht, manchmal doch.
Eine syntaktische Besonderheit besteht bei Attributen,, die wie An/Aus Schalter funktionieren (in Programmiersprachen sind sie vom Typ bool oder boolean). Hier bedeutet die pure Existenz des Attributs, dass der Schalter an ist. Ist das Attribut nicht da, ist der Schalter aus.
Exkurs: Überraschungen
HTLM ist nicht logisch und nicht konsistent.
Überraschung 1
Einschalten, indem man ausschaltet.
<video controls="false" ...>
Schaltet das Bedienfeld bei einem video Element ein, nicht aus. Geprüft wird, ob das Attribut controls vorhanden ist oder nicht.
Überraschung 2
Die Tücke mit den Anführungszeichen.
<div name=Hallo-Tach>
<div name="Hallo Tach">
<div name=Hallo Tach>
Zeile 1 weist dem Universal-Attribut name den Wert Hallo-Tach
zu; ein Wert, ein Wort.
Zeile 2 weist dem Attribut den Wert Hallo Tach
zu, ein Wert bestehend aus zwei Wörtern.
Zeile 3 weist dem Attribut name den Wert Hallo
zu und schaltet das - nicht vorhandene - Attribut Tach an.
Die Tücke mit den Anführungszeichen, diesmal anders.
<div class=Hallo-Tach>
<div class="Hallo Tach">
<div class=Hallo Tach>
Zeile 1 weist dem Universal-Attribut class den Wert Hallo-Tach
zu. Danach gehört das div Element zur Klasse Hallo-Tach
.
Zeile 2 weist dem Attribut class zwei Werte zu. Das Element gehört danach zur Klasse Hallo
und zur Klasse Tach
.
Zeile 3 weist dem Attribut class den Wert Hallo
zu und schaltet das - nicht vorhandene - Attribut Tach an.
Häufig verwendete Attribute
Es gibt rund 20 Attribute, die jedem Element zugeordnet werden können, sog. Universalattribute. Darüber hinaus gibt es noch mal 100+ Weitere, die nur bei manchen Elementen erlaubt sind.
Obwohl das eine ganze Menge Attribute sind, muss man sich als Autor nur sparsam mit Attributen auseinandersetzen.
id und class
Die wohl am häufigsten gebrauchten Attribute sind die Attribute id und class. Es sind Universalattribute, d.h. sie können in jedem Element verwendet werden.
- id
-
Das Attribut id identifiziert ein Element innerhalb eines Dokumentes eindeutig. Damit ist dieses Element durch CSS oder JavaScript gezielt und einzeln ansprechbar. Die Beziehung zwischen id und Element ist ein-eindeutig, d.h, ein Element kann nur eine id haben und eine id bezieht sich auf genau ein Element.
Der Autor muss sicherstellen, dass der Wert einer id eindeutig ist, der Browser tut das nicht. Der Browser merkt sich das erste Vorkommen einer bestimmten id und ignoriert alle Anderen.
Das id Attribut dient auch als Ziel, das von innerhalb des HTML Dokumentes angesprungen werden kann oder bei sog.deep links
einen Einsprungpunkt in das Dokument bietet. - class
- Das Attribut class ordnet ein Element einer Klasse zu. Damit kann dieses Element zusammen mit allen anderen Elementen dieser Klasse von CSS oder JavaScript selektiert oder heraus gefiltert werden. Im Gegensatz zu id ist diese Zuordnung nicht eindeutig. Zu einer Klasse können mehrere Elemente gehören und ein Element kann auch zu mehreren Klassen gehören.
<h2>Zusammenfassung</h2>
<p>Dieser Punkt in einem Dokument kann angesprungen werden.</p>
</section>
commentund
hide
Elemente in der Klasse <q>comment</q> können als Kommentar gekennzeichnet
werden. Wenn man will.
</p>
<div class="hide">
Elemente in dieser Klasse können bei Bedarf versteckt werden.
</div>
<p class="comment hide">
Mehrere Klassen trennt man durch Leerzeichen.
</p>
href und src
Diese Attribute spielen eine wichtige Rolle beim Umgang mit Hyperlinks und beim Zugriff auf externe Ressourcen. Es sind keine Universalattribute, d.h. sie können nur bei bestimmten Elementen verwendet werden, die dazu gedacht sind, diese Art von Zugriff zu ermöglichen. (Siehe dazu die Abschnitte über Hyperlinks und eingebettete Objekte.)
- href
- Das Attribut href ist die Abkürzung von Hyper REFerence und adressiert ein Ziel oder eine entfernte Quelle per URL. Das href Attribut darf nur in 4 Elementen (a, link, area, base) verwendet werden, wobei man allerdings zumindest das Element a dauernd einsetzt. Mit a werden andere Seiten oder andere Stellen in der aktuellen Seite verankert (Daher der Name a=anchor). a ist das Element, mit dem man surft und sein Attribut href ist das jeweilige Ziel.
- src
- Auch das Attribut src ist ein externer Verweis und ist die Abkürzung für SouRCe (Quelle). Allerdings verweist src immer auf eine externe Quelle, die geladen wird und nicht auf ein Ziel, das angesprungen wird. src darf in 9 Elementen eingesetzt werde, die alle - außer script, das eine JavaScript Datei lädt - irgendetwas mit eingebetteten Objekten zu tun haben. Der Wert von src ist eine URL. Die Datei hinter der URL wird vom Browser geladen und - je nach Element - entsprechend verwendet. Am Häufigsten wird src wahrscheinlich als Attribut des Elementes img verwendet und verweist auf eine externe Bilddatei.
href
<link rel="stylesheet" href="bsp.css">
</head>
<body>
<a href="start.html">Start Surfing</a>
<a href="#summary">Zusammenfassung</a>
</body>
- Das Vorkommen von href im Head lädt eine CSS Datei.
- Das erste Vorkommen von href im Body lädt eine andere Datei in den Browser, mit der die aktuelle Datei ersetzt wird.
- Das zweite href im Body ist eine Sprungadresse innerhalb derselben Datei.
src
<script src="src/js/bsp.js"></script>
</head>
<body>
<img src="img/cerberus_160x160.webp" alt="Bild: Hund.">
</body>
- Das erste src lädt eine JavaScript Datei und führt sie aus.
- Das zweite scr lädt ein Bild und zeigt es an.
Document Object Model (DOM)
Innerhalb des Browsers werden die Elemente eines HTML Dokuments in dem sogenannten Document Object Model (DOM) angeordnet.
Das DOM ist eine Baumstruktur, eine Hierarchie von Knoten. Jeder Knoten kann mehrere Kind-Knoten haben, aber immer nur von einem Eltern-Knoten abstammen. Die meisten dieser Knoten sind Elemente. Es gibt auch andere Knoten, die uns im Moment aber nicht interessieren.
Für jedes HTML Dokument gibt es genau ein DOM. Ok, es gibt auch sog. shadow DOM's. Aber auch das interessiert hier nicht.
Das Wurzelelement des DOM ist das html
Element, das Element, das durch die Marken <html> und </html> bestimmt wird.
Da das DOM streng hierarchisch aufgebaut ist, sind alle zwischen den Marken <html> und </html> definierten Elemente Kind-Elemente des Wurzel-Elements. Und zwischen den Marken der Kind-Elemente definierte Elemente sind wiederum Kind-Elemente der Kind-Elemente.
Damit hat jedes Element (außer html
selber) genau ein Eltern-Element als direkten Vorfahren.
Man muss diese Struktur nicht genau verstehen, man sollte aber im Hinterkopf behalten, dass es sie gibt.
Alle Elemente erben die Eigenschaften von allen ihren Eltern-Elementen in der Reihenfolge des DOM, also von der Wurzel durch die Verzweigungen in Richtung Blätter.
Der Inhalt von h1 ist sowohl ein Kind von html als auch von body als auch von h1. In genau dieser Reihenfolge werden Eigenschaften der Eltern-Elemente auf den Text Hallo Tach
angewendet. Und überschrieben!
Technisch gesehen ist der Inhalt eines Elementes ein eigenständiger Knoten.
Grafischer Auszug aus dem DOM.
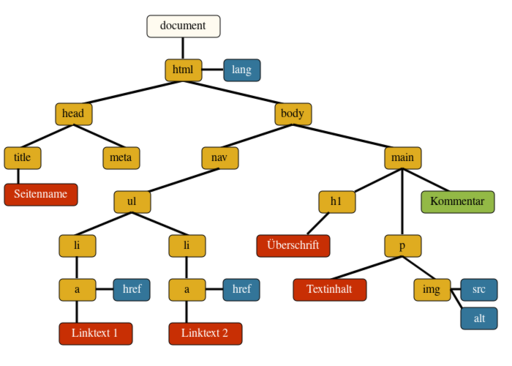
Diese Darstellung findet sich bei selfhtml auf der Seite JavaScript/DOM.
Das DOM eines Beispiels als Text.
Der Quellcode.
Der Text "html (Wurzel)" und "head" ist an den hier gezeigten Stellen komplett unzulässig und sinnlos. Außer man macht eine Demo und hofft darauf, dass die Browser es schlucken.
Die Beispiele zeigen, dass die Wurzel des DOM das Element html ist und die Elemente head
und body die beiden einzigen direkten Unterelemente sind. Alle drei sind Teil des DOM.
Wichtig ist ein tieferes Verständnis des DOM, wenn man mit JavaScript arbeitet. Hier, an dieser Stelle, geht es nur um die Begriffsklärung und einen groben Eindruck.
Einteilung von Elementen
Ein Versuch
inline
und block
Elemente
Begriffsbestimmung und Abgrenzung
Elemente unterscheiden sich danach, wie sie sich im Textfluss verhalten. Manche sind dazu gedacht, einzelne Wörter, Wortgruppen, Teilsätze oder Teile einer Zeile zu markieren, andere Elemente beziehen sich auf Absätze, komplette Objekte und definieren Blöcke im Dokument.
Die Elemente, die sich auf Teile einer Zeile beziehen, werden inline
Elemente genannt, diejenigen, die Objekte oder Absätze beinhalten, werden block
Elemente genannt.
Block-Elemente führen immer dazu, dass Browser vor und nach den Elementen einen Zeilenumbruch einfügen und sie gehen immer über die ganze Seitenbreite.
Inline-Elemente fügen sich immer in eine Zeile ein und folgen dem normalen Fluss der Textaufbereitung.
Das mit Sicherheit am häufigsten benutzte Blockelement ist <p>, der Paragraf oder Absatz. Allerdings ist p kein ganz normales Blockelement. Einmal wird bei der Darstellung vor und nach dem Text zwischen <p> und </p> von den meisten Browsern zusätzlicher Leerraum eingefügt. Zum anderen können p Elemente nicht geschachtelt werden. Beides ist bei normalen Blockelementen anders.
Das klassische und neutrale Block-Element ist <div> und das entsprechende inline
Gegenstück ist <span>. Beides sind Elemente, die keine eigene Bedeutung haben und nur dazu dienen, einen bestimmten Ausschnitt des Dokumentes zu markieren. Das Eine in einem Block-Kontext, das Andere in einem Inline-Kontext.
Beispiele
Hier ist der Quelltext mit Block- und Inline-Elementen durcheinander:
Und hier ist das Ergebnis:
Elemente mit und ohne schließende Marke
Muss. Kann. Darf nicht
Generell wird ein Element durch eine öffnende und eine schließende Marke bestimmt. Zwischen diesen Marken steht der Inhalt des Elementes. Es gibt aber Elemente, bei denen eine schließende Marke syntaktisch nicht notwendig oder gar verboten ist.
Für die schließende Marke gibt es drei Möglichkeiten:
-
Die schließende Marke ist notwendig.
Das gilt für die meisten Elemente. Die öffnende und die schließende Marke begrenzen den Inhalt des Elementes. -
Die schließende Marke ist verboten.
Das gilt für wenige Elemente wie<br>,<hr>,<meta ...>,<img ...>,<link ...>. Diese Elemente haben schlicht keinen Inhalt, können also auch nicht abgeschlossen werden. -
Die schließende Marke ist nicht notwendig, aber auch nicht verboten.
Das gilt für wenige Elemente bei denen die Begrenzung des Inhalts aus dem Kontext ermittelt werden kann. Das bekannteste Beispiel hierfür ist<p>, der Paragraf.
Bei den Elementen, die keinen Inhalt und deshalb auch keine schließende Markierung haben, gibt es einmal solche, die für sich alleine eine Funktion besitzen (z.B. br
, der Zeilenumbruch) oder solche, deren Zweck ausschließlich über ihre Attribute definiert wird (z.B. meta
oder img
).
Über die Verwendung von nicht notwendigen schließenden Marken gibt es in der Welt unterschiedliche Meinungen. Die eine Ansicht ist, nicht Notwendiges sollte am Besten gar nicht erst geschrieben werden. Die andere Auffassung ist, ein konsistenter Stil sei besser als einer, bei dem mal geschlossen wird und mal nicht.
Unabhängig von dieser Diskussion sollte jeder, der anfängt mit HTML zu arbeiten, alle Markierungen wieder schließen. Es ist etwas undurchsichtig, bei welchen Elementen eine schließende Marke überflüssig ist und bei welchen nicht. Bis man diesen Wissensstand erreicht hat, sollte man ganz brav alles wieder zumachen, was man mal aufgemacht hat.
Mit und ohne schließende Marken.
Mit und ohne schließende Marken. Der Quelltext.
Technische und semantische Elemente
Gegenüberstellung
Die Unterscheidung in semantische
und technische
Elemente ist etwas gewagt. Zwar findet sich der Bergriff semantische Elemente
auch in der Literatur, um neue Elemente von HTML5 hervorzuheben. Eine Definition oder gar eine direkte Gegenüberstellung zu technischen Elementen
gibt es allerdings nicht.
Eine scharfe Abgrenzung bzw. Zuordnung ist auch in vielen Fällen gar nicht möglich, trotzdem ist dieses Begriffspaar in meinen Augen sinnvoll, um in manchen Fällen eine Entscheidungshilfe zu liefern.
Will ich etwas fett gedruckt haben, benutze ich bold, wenn ich etwas stark hervorheben möchte, benutze ich strong. Das ist oft dasselbe, aber eine starke Hervorhebung muss nicht immer im Fettdruck enden, es können auch Großbuchstaben werden, eine andere Schriftart oder kursiv. Dagegen ist es einfach irritierend, wenn die Anweisung fett
dazu führt, dass das Folgende kursiv geschrieben wird.
Die semantischen Elemente fangen also eher das auf, was Autoren meinen, die technischen Elemente sind dagegen direkte Anweisungen an den Browser, etwas auf eine bestimmte Art umzusetzen.
Semantik ist die Lehre von der Bedeutung von Sätzen und Begriffen. Sie beschäftigt sich mit der Beziehung von Ausdrücken zu ihrem Inhalt. Parallel dazu existiert die Syntaktik, die sich mit den Beziehungen von Ausdrücken untereinander beschäftigt.
Etwas kann syntaktisch gesehen korrekt, semantisch gesehen dagegen kompletter Unsinn sein.
Semantische Elemente haben die Aufgabe, das Dokument unter inhaltlichen Gesichtspunkten zu strukturieren. Sie sollen Autoren die Möglichkeit geben, in einem Dokument Dinge hervorzuheben, am Rand zu bemerken, Kapitel zu bilden oder, oder, etc., ohne das damit zwangsläufig irgendeine Art der Darstellung verbunden ist.
Dagegen gibt es Elemente, die in erster Linie für den Browser gedacht sind und mit der inhaltlichen Strukturierung weniger zu haben. Das sind Elemente, die die Darstellung unmittelbar beeinflussen oder aus technischen Gründen das DOM modifizieren.
Beispiele
Semantische Elemente ohne eigenes Layout
Diese Elemente haben erst einmal keine Auswirkungen auf die Darstellung, sie dienen nur der Ordnung und Struktur des Inhalts. Die Namen der Elemente sind sprechend, d.h. aus den Namen geht hervor, was sie bewirken sollen.
Technische Elemente ohne eigenes Layout
Diese Elemente sind von der Bedeutung her neutral und dienen nur dazu, einen Teil des Dokumentes zu markieren, so dass er gezielt ansprechbar ist. Ohne weitere Zusätze, üblicherweise Attribute, machen diese Elemente überhaupt keinen Sinn.
Semantische Elemente mit eigenem Layout
Diese Elemente strukturieren das Dokument inhaltlich und werden vom Browser mit einem passenden Layout versehen.
Technische Elemente mit eigenem Layout
Diese Elemente haben unmittelbare Auswirkungen auf die Darstellung, bzw. sind Hinweise für den Browser, wie er den Inhalt eines Elementes zu behandeln hat.
Eine Demo semantischer Elemente
Semantische Elemente: Demo
Die Farben in diesem Beispiel sind durch CSS definiert.
Die Farben in diesem Beispiel sind durch CSS definiert.
Zum Schluss ein Tipp, Hinweis, Anregung:
Das Layout aller Elemente kann - und soll - per CSS bestimmt werden. Auch das Layout von Elementen, die schon ein Standardlayout haben, kann durchaus verändert werden.
Häufige Elemente
Elemente, die man immer braucht
Es gibt in HTML - wie in jeder Sprache - eine geringe Zahl von Wörtern, Begriffen oder Befehlen, mit denen man das meiste, was man ausdrücken will, auch ausdrücken kann.
Gering ist natürlich relativ, wie immer. Es gilt die 80 / 20 Regel.
Was man braucht
Es gibt wahrscheinlich irgendwo im Netz eine Statistik der am meisten benutzen HTML Elemente. Da ich die aber nicht gefunden habe, müssen wir hier ohne auskommen.
- Absatz:
<p> - Das wohl am häufigsten benutzte Element und die einfachste Art, Absätze zu erzeugen.
- Überschriften:
<h2>bis<h4> - Die wesentliche Überschriften innerhalb eines Dokumentes. Sie sind die wichtigsten sichtbaren Gliederungselemente in einem Dokument. Sie sollten zusammen mit Sektionen oder Artikeln benutzt werden.
- Listen und Aufzählungen:
<ul>oder<ol>mit<li> - Aufzählungen und unsortierte Auflistung mit Nummern oder Spiegelstrichen versehen.
- Hyperlinks:
<a> - Der Anker für einen Sprung zu einer Seite im WWW oder an eine Stelle im Dokument. Hyperlinks ermöglichen das Surfen und das Erstellen von Inhaltsverzeichnissen.
- Sektionen oder Abschnitte:
<section> - Gruppierung von Paragrafen oder anderen Elementen nach inhaltlichen Kriterien. (Auf der selben Ebene liegt der <article>; er wird aber seltener benutzt.)
- Blockmarkierungen:
<div> - Gruppierung von Elementen unter technischen Gesichtspunkten.
- Hervorhebung:
<strong>,<em> - Markierung eines Teils einer Zeile, um ihn zu betonen. Die einfachste Form, um etwas hervorzuheben.
- Textmarkierung:
<span> - Markierung eines Teils einer Zeile aus technischen Gründen.
Beispiele
In dem folgenden Beispiel werden alle möglichen Elemente verwendet, mit denen man ein strukturiertes HTML Dokument erstellen kann. Das Dokument sieht nicht sehr schön aus und ist inhaltlich völlig sinnlos.
Oft benutzte Elemente: Beispiele (Quellcode)
Oft benutzte Elemente: Beispiele
Was fehlt
Fehlende Befehle, Beschreibungen, Features
Die ganze Doku besteht aus Lücken. Es gibt ganz viel, das fehlt und dagegen lässt sich nicht viel machen.
Es gibt aber ein paar Sachen, die ganz bewusst und mit Absicht nicht erwähnt werden. Entweder, weil sie im HTML Standard fehlen, also gar nicht da sind oder weil man sie besser nicht benutzen sollte.
- Das Element base
-
Das Element base existiert und kann im head dazu benutzt werden, ein Basis-URL für das Dokument festzulegen.
Richtig implementiert, könnte es bei der Verwendung von Hyperlinks jede Menge Schreibarbeit sparen und vor allem die Portierbarkeit einer Website erhöhen.
Leider wird das in base gesetzte Wurzelverzeichnis von den Browsern gnadenlos vor alles gesetzt, was in einem href steht.
Setze ich z.B.<base href="https://meinedomain.de/">dann wird ein Statement<a href="#sektion1">(z.B. in einer Inhaltsangabe) aufgelöst in: <a href="https://meinedomain.de/#sektion1">, was nicht das ist, was ich wirklich haben will.
Also: Finger weg von base. - Das Element table
-
In einer HTML Dokumentation nimmt das table Element oft viel Raum ein. Das hat historische Gründe: Bevor die CSS Attribute flex und grid im letzten Jahrzehnt eingeführt wurden, wurde table zweckentfremdet dafür verwendet, Elemente horizontal anzuordnen. Da eine solche Möglichkeit in HTML und CSS bis dahin nicht existierte, war table ein extrem wichtiges Layout Instrument.
Heute wird table nur noch dann verwendet, wenn man in einem Dokument Daten darstellen will, die von der Natur der Sache her eine Tabelle sind. Das passiert den meisten Leuten nicht so häufig. Man braucht in HTML das Element table genau so häufig, wie man in einem Textdokument eine Tabelle braucht, nämlich äußerst selten. - Das Attribut style
- Das Attribut style bietet die Möglichkeit, CSS direkt im Kopf eines Elementes zu implementieren. Dieses Attribut sollte man tunlichst nicht verwenden. Es ist schlechter Stil und macht, wenn man es naiv verwendet, später jede Menge Ärger. Es ist besser, man kennt es gar nicht.
- Alle obsoleten Eigenschaften von HTML
-
Mit HTML5 sind viele Elemente und Eigenschaften obsolet geworden, die früher Aufgaben übernommen haben, die heute von CSS erledigt werden.
In der Literatur werden diese Elemente auch heute noch, teilweise ausführlich, beschrieben, um dann anzumerken, dass sie obsolet sind.
Hier werden sie gar nicht erst erwähnt. - Alle JavaScript bezogenen Attribute
-
Es gibt einige Attribute, die direkt JavaScript aufrufen. Diese Attribute sollte man, außer für
Schnellschüsse
, nicht verwenden. Daher werden sie hier auch nicht beschrieben.